Chapter 2. The Graph Model: Networks of Concepts
In this chapter we describe the first and simplest of our models for
the meanings of words, and in particular the meanings of nouns. By
observing which pairs of nouns occur together in a large collection of
texts, we will build and explore a network or graph where each
noun is represented by a node with links to nouns which
are similar in meaning. At least, that is the plan, though as we will
see, the model throws out a few howlers as well as good links. In
this way, our case study highlights some of the pitfalls --- and the
benefits --- of building mathematical models directly from text data,
and will hopefully raise some questions for the reader about how
appropriate our model is for representing the meanings of words. As
with any mathematical model for real-world phenomena, there is a
trade-off between how exactly we want the model to describe the
real-world situation, and how difficult the model should be to build
--- and to a large extent, the balance between these issues is
mediated by the purpose for which the model is intended.
Before we describe the graph model itself, we will go through three
preliminary stages. In Section 2.2, we describe some
of the resources and tools for natural language processing that form
a starting point for our investigations, and then in Section
2.3 we give a very brief introduction to what
we mean by a graph. But before either of these, readers may find it
well worthwhile to consider some of the issues behind defining words
in terms of their similarities with other words.
Sections
1. Similarities between words
Is it circular to describe words in terms of the words that they are
similar to? Of course, but it's certainly useful - so useful that Dr
Peter Roget used the ides to give us one of the classic reference
works of all time, the thesaurus. Geometry is all about
relationships rather than absolute essences, and has no objection at
all to such an approach. There are many modern versions of the
thesaurus idea, and in many ways our automatic tools for analysing
language produce output much more like a thesaurus than a dictionary.
2. Some Tools and Terminology in Natural Language Processing
Corpora, types and tokens, part-of-speech tags - and introduction to
some of the tools of a computational linguist's trade. This material
is not diffficult to understand, and it is very useful for
understanding the rest of the book. In particular, a corpus gives us a
large collection of natural language texts to extract information
from, and part-of-speech tagging enables us to work out automatically
which of the words in the corpus are nouns. This is enough information
for a computer to build a large graph of nouns and the way they are
related to one another.
3. What is a Graph?
The Bridges of Konigsberg, the London Underground, a model of a
thesaurus or just a collection of nodes and links.
|
|
|
| The Bridges of Konigsberg |
The London Tube |
A simple graph |
In a graph, each item is modelled my a node, and its
relationships with other items is described by a collection of
links. Leonhard Euler used this idea in the 18th century to
prove that it is impossible to walk over each bridge in Konigsberg
once and once only, because more than 2 of the nodes (land masses)
have an odd number of links (bridges). Since then, graphs have proved
to be a very simple, very general, and very useful idea.
4. Building a Graph of Words from Corpus Data
Nouns that occur in lists are often related to one another - for
example, in the sentence
"Ship laden with nutmeg, cinnamon, cloves or coriander once battled
the Seven Seas to bring home their precious cargo."
the nouns nutmeg, cinnamon, cloves and
coriander are likely to be related in some way. In general,
nouns that occur with the words "and", "or", or a comma in between
them are often related. After extracting such patterns from the
British National Corpus (100 million words of English text), we had a
very big graph representing nearly 100,000 nouns and 500,000 links.
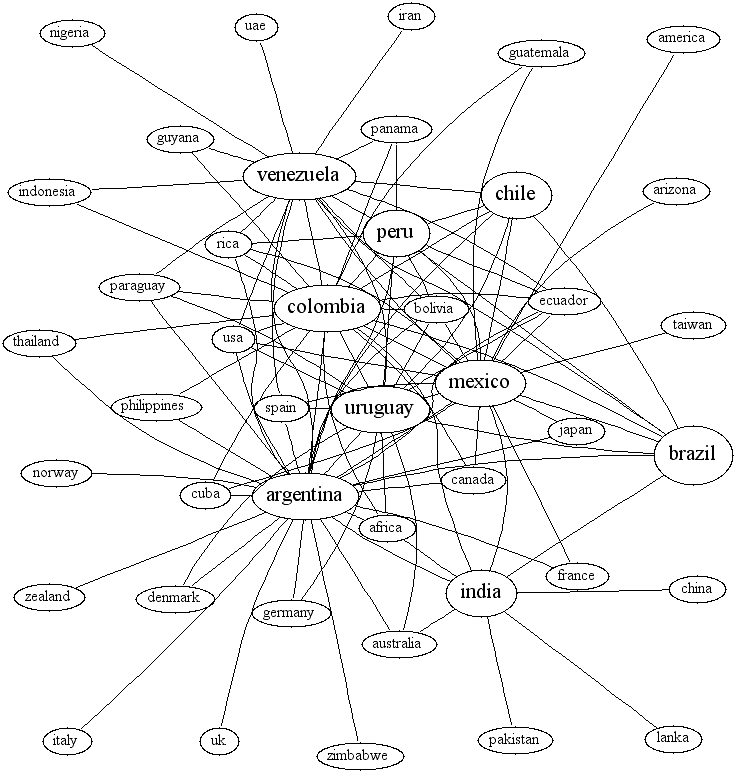
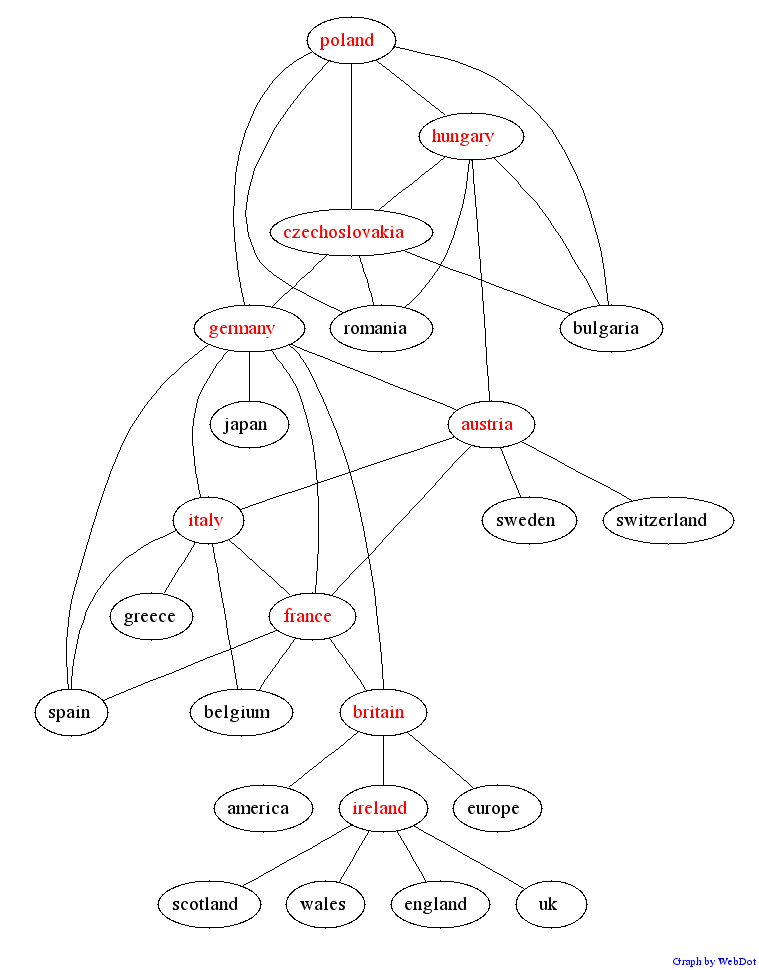
5. Exploring the graph
Take a tour! These graphs of countries and their relationships were
both built just by a computer reading ordinary text.
6. Symmetric relationships
Most of these links are "symmetric" in nature - if you see "football
and cricket" in text it's likely that you could see "cricket and
football." Many of the relationships we meet later in the book are not
symmetric.
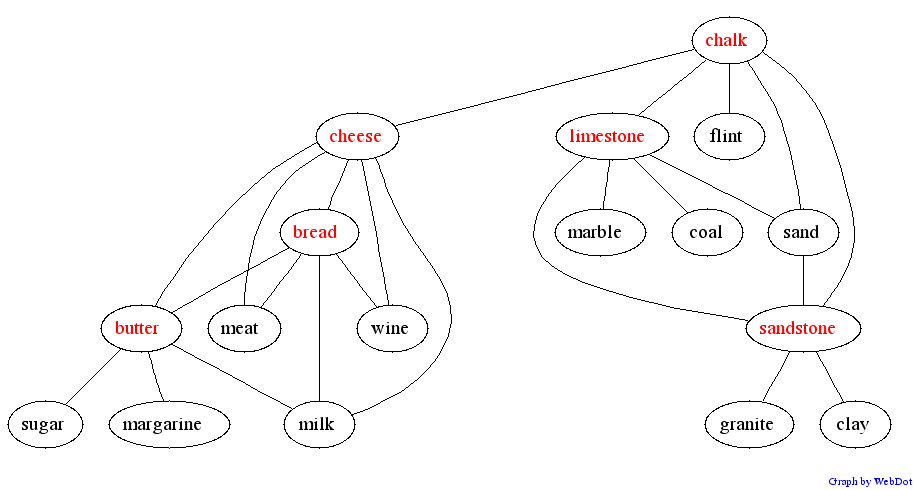
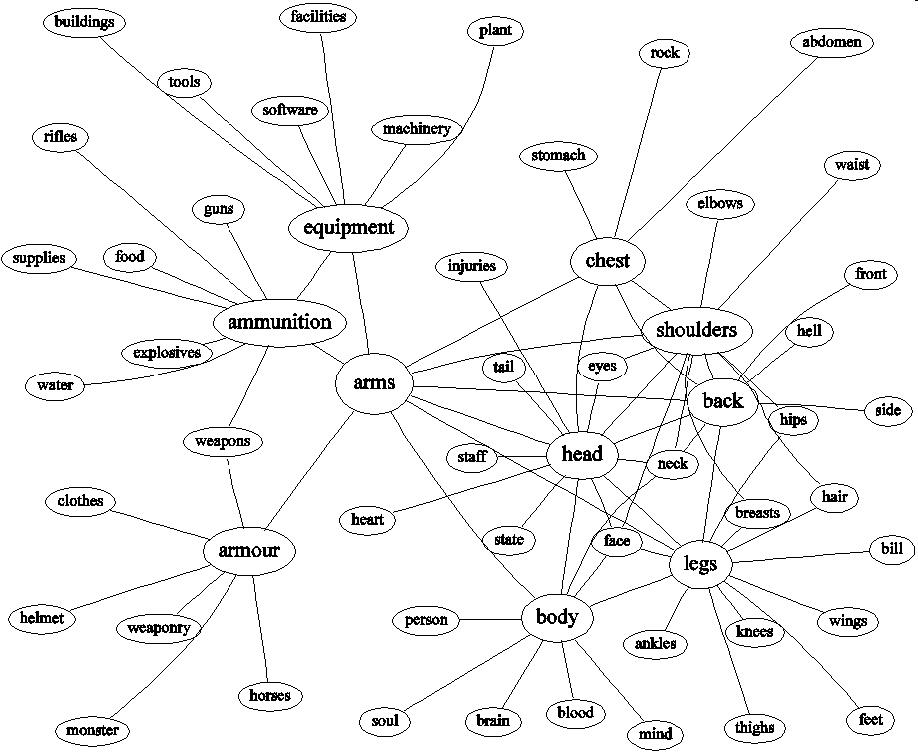
7. Idioms and Ambiguous Words
The graph model even behaves appropriately in the vicinity of an
ambiguous word or an idiomatic link. Idioms often give rise to link
between two otherwise separate clusters, giving a "pair of scales"
shape. Ambiguous words are often nodes sitting between two clusters,
looking like the knot in the middle of a "bowtie" shape.
Examples and Demo
This chapter contains many example pictures of word-graphs built
automatically from free text.
References
The following papers describe and evaluate this work more technically:
-
Dominic Widdows and Beate Dorow.
A Graph Model for Unsupervised Lexical Acquisition.
19th International Conference on Computational Linguistics,
Taipei, August 2002, pages 1093-1099.
-
Beate Dorow and Dominic Widdows,
Discovering Corpus-Specific Word Senses.
EACL 2003, Budapest, Hungary
Conference Companion (research notes and demos) pages 79-82